One thing I have noticed in all my years as a data professional: few users understand (or care) how far away they are from their data. Quite often they expect instant results from their queries. They don’t understand the upper bounds of resources like network bandwidth, the speed of light, and that the data is located on the other side of the world.
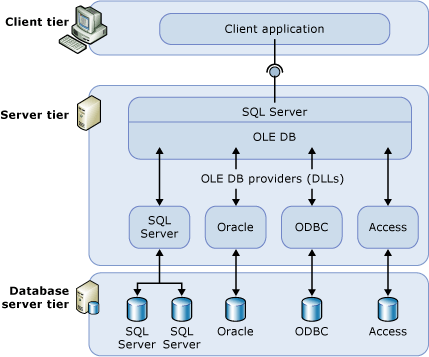
SQL Server makes it easy to connect to and query data from remote data sources. The common way of getting this done is through the use of a linked server, which is little more than an OLEDB data source.
The beauty of a linked server connection is that it allows an end user to write a query that looks like any other T-SQL query. For example, here is a query against a local table:
SELECT col1, col2 FROM [databasename].[schemaname].[tablename]
And here is a query that would be written that would utilize a linked server:
SELECT col1, col2 FROM [linkedservername].[databasename].[schemaname].[tablename]
To someone with an untrained eye they would think the data is as easily accessible as any other. You don’t have to do anything special to write a query against a remote data source. All you need is the name of the linked server.
But the dirty little secret here is that SQL Server is going to make decisions for you as to how to mash all the data together and return you a result set.
People love using linked servers. Because data can (and does) exist everywhere, users naturally want to write one query that joins as much data as possible with no regard if it is local or remote. Even a DBA with many servers to manage will be tempted to build out a series of linked servers to capture monitoring details in a central location.
There is also the case where data is going to be too big or cumbersome to move around easily. In that case you are going to want the query to be executed on the remote server and only return the data that is needed across the network. What this means that you should make an effort to help SQL Server make the right choices.
Here are the top three issues I have seen when it comes to linked server (AKA Distributed Query) performance:
1. Insufficient Permissions
Without a doubt this is the number one reason for why linked server query performance suffers. Historically in order for SQL Server to take advantage of using statistics on the remote server then the login used to make the connection on the remote servers needed sufficient rights. The role needed would have been one of the following:
- sysadmin
- db_owner
- db_ddladmin
If you don’t have sufficient permissions then you aren’t able to use stats. This is killing your performance across linked server connections. So for everyone that has been assigning the db_datareader role to remote logins you are sacrificing performance for security. While that may be an acceptable tradeoff in your shop, I am willing to wager that most admins have no idea about this silent performance killer.
A good example of identifying these symptoms are contained in this article: http://www.sql-server-performance.com/2006/api-server-cursors/
In SQL 2012 SP1 the permissions to view the statistics on an object have been modified so that a user with SELECT permission would be able to use the stats on the remote tables. Check this link for more details in the ‘Permissions’ section towards the bottom.
2. Query join syntax
Conor Cunningham gave a great talk at SQLBits X on Distributed Queries. In that talk he discussed some different join types and whether or not they were good candidates to be executed remotely. For example, a simple query that wants to pull data from just one remote table is likely to be executed remotely and only pull back the necessary rows. But what about a join between one small local table and one large remote table? What happens then?
You’ll need to watch the video to listen to Conor explain all the nuances of distributed queries. The lesson I learned from the talk is simple: when possible, give the optimizer some help. If you can rewrite your query to pull back the smallest rowset possible from the remote server, the better chance that query will be executed remotely.
3. Functions
Some functions, like GETDATE(), won’t be executed remotely. This make complete sense to me because if I am trying to execute (and filter) a set of data on a remote server (where the time could be very different than the local server) then the concept of GETDATE is lost due to the fact that the servers could be in multiple timezones. SQL Server knows this and as a result it likely won’t execute the query remotely.
OK, let’s say you have identified a linked server query that is not performing well. What can you do?
The way I see it, you have two options available for helping to tune a linked server query.
The first option is to force the query to run remotely. This is done by using the OPENQUERY() function. This function will force query execution on the remote server. By default this option will use permissions defined in the linked server. We’ve already talked about the potential issue with permissions up above, so I won’t do that again here.
The second option is to try rewriting the query. (I know many developers that just screamed at me to “STOP BLAMING THE CODE!”) Start with one table, add the necessary predicates, then add additional tables and predicates until the results change from remote execution to local. Once identified you can then go about exploring some rewrite options.
I’ve been writing queries for linked servers for about a dozen years now. These are the top three performance killers I have found to be common to many shops. Microsoft has done well to help remedy the permissions issue. However they are not so good as to write your queries for you (at least not yet). Until then, you are going to want to test your queries to make certain that they are behaving as expected.
[If you liked this post and found it useful, head over to my SQL Server Upgrades page to get details on how to upgrade your instance of SQL Server.]

Well, great article. I wouldn’t thought of point 1, very interesting.
Thanks.
Thanks!
Yep, indeed. Me neither! Thanks for sharing, Thomas!
+1 on what SE said. I assumed that SELECT permissions always included rights to view stats for the target table.
Nostalgia! Remembering those days of using OpenQuery to pull DB2 data from a JDE System. Nice post.
Yes, this was a trip down memory lane for me, too.
Forgot to mention how when we tried to pull too much data from DB2 it would just hang and after canceling the query you could no longer use the Linked Server until you restarted SQL Services. Lovely days.
Yeah, and the “mem-to-leave” errors in SQL2000…
Please don’t mention SQL 2000 I’m just barely starting to recover.
@Ayman, thanks for your post. I’ve been having this same issue with MSSQL2000 using a KBSQL linked server. Until now, the only fix I’d found effective was to reboot the SQL server. Good to know I can just restart the services. 🙂
Still doing that here. SQL 2012 and the nly way in to the progress ( oh, yeah…) DB is via (get ready) ODBC, and you know if someone is only going to write an ODBC interface it is going to be a crappy one.
Good one..didnt think the first one..always assumed that select comes with stats view permissions..
Just to clarify point 1 & SQL 2012 SP1. Does it kick in when running a query from SQL 2012 SP1 to a linked server for a lower version SQL or vice versa? I guess it’s the vice versa? Thanks!
Dbee,
The target data source needs to have sufficient permissions. If you are using SQL 2012 SP1 on one end (ServerA), and a different version on the other (ServerB), then you should take care to make certain the permissions are correct for ServerB.
HTH
Hi Thomas, regarding point 1: yes, the permissions you are referring to are about running the DBCC SHOW_STATISTICS command; however, any query run by a login with just SELECT permissions will kickstart the sql optimizer, which in turn will make use of the available statistics. So I am a little puzzled by point 1, to be honest.
Marios,
The link I provided in the post explains it clearly: http://technet.microsoft.com/en-us/library/ms174384.aspx
For version of SQL prior to SQL 2012 SP1, the user running the remote query needs to have sufficient permissions.
In many environments the use of the db_datareader database role is given in order to allow logins the ability to read data remotely. These permissions were not sufficient.
HTH
I’m still confused. Are you saying that a query run by a login with just db_datareader permissions does not enlist the query optimizer and by extension does not have access to cardinality and stats information? Again the link you mention refers to permissions for running the DBCC SHOW_STATISTICS command. I don’t think this has anything to do with query performance.
I think the statement “If you don’t have sufficient permissions then you aren’t able to use stats” is incorrect, especially in the context of which you are talking about.
Marios,
Scroll down to the ‘Permissions’ section for that MSDN link. It is very clear:
In order to view the statistics object, the user must own the table or the user must be a member of the sysadmin fixed server role, the db_owner fixed database role, or the db_ddladmin fixed database role.
SQL Server 2012 SP1 modifies the permission restrictions and allows users with SELECT permission to use this command. Note that the following requirements exist for SELECT permissions to be sufficient to run the command:
Users must have permissions on all columns in the statistics object
Users must have permission on all columns in a filter condition (if one exists)
To disable this behavior, use traceflag 9485.
So, prior to SQL 2012 SP1, having SELECT permissions was not enough.
HTH
Understood, but how does that affect performance? How does it affect the query plan? There should be no impact there.
Marios,
The optimizer uses stats to build a plan. If it can’t access stats, then it builds a plan anyway, albeit one that is likely to be less than efficient.
HTH
This goes against everything I thought I knew about how the sql optimizer works. Do you have any evidence to support the claim that select-only permissions produce “worse” plans than more elevated permissions?
Marios,
Sorry for the disconnect here, I’m not sure what else to provide besides the links I’ve already given.
Here’s something from Joe Sack, perhaps this will help? http://www.sqlskills.com/blogs/joe/distributed-query-plan-quality-and-sql-server-2012-sp1/
Thank you for the link.
It seems this issue has been fixed with SQL 2012 SP1? Also, this appears to me to be an issue with distributed queries only? I have to say I am shocked that security settings could affect performance; I never thought there was such a link. If you could present an article at a future date exploring this issue further – especially with local, non-distributed queries – it would be appreciated.
This certainly should not be the case. I mean, granting someone readonly permissions should not penalize them performance-wise. Just because you want prevent someone from overwriting data in a database, should not make their queries slower!
Thanks for your time, I learned something new from all this.
Marios
Correct, the issue is for distributed queries only.
Thomas, sorry to bug you again, but I have one more question/clarification.
In our shop we make heavy use of linked servers that we configure to use the security context of remote logins (bottom setting of the Security tab in “Linked Server Properties” dialog). These “remote” logins have only db_datareader access on the target server dbs. If I understand this correctly, these linked-server connections would be affected performance-wise by the inability of the “remote” login (local login on the target) to view statistics.
I’m asking because linked-server security can be configured in other ways; eg. by “using the login’s current security context” (2nd last radio button of the Security tab in “Linked Server Properties” dialog).
Does the view-stats limitation apply to all possible linked-server security settings?
Thanks again for your time,
Marios
Marios,
Yes, that is my understanding of how distributed queries work. Using the current security context would still be an issue if the permissions were db_datareader only (for example).
Don’t forget about EXEC (”) AT .
I wrote a blog post about #1 a while ago. In short, you can get around the egregious permissions requirements with a little module signing of some system objects. Check it out.
http://www.spartansql.com/2012/10/cardinality-estimates-over-linked-server.html
Ben,
That’s an interesting workaround! I would have never thought to use a certificate in that manner.
Thanks for sharing!
Tom
Excellent article, and very relevant to my tasks right now.
Thanks Matt, glad I could help!
Good Post. Really liked the 1st point that we are not aware of. Need to test it today:)
Thanks a ton!!
Point #1 : Good one. Shall test it today
Is there a way to use tables that may or may not exist via linked servers?
It doesn’t work for me because the pre-flight testing always checks for it, unlike with local queries. I can use Dynamic SQL but that will open the doors for SQL injection.
Sorry, I don’t understand the question. You are querying against a table that may not exist?
Yeah, like with regular local tables I can use IF OBJECT_ID(‘tableX’) IS NOT NULL
SELECT x FROM tableX
With linked servers, if tableX doesn’t exist, it will not allow the query. I believe this is because while trying to make the execution plan it wants to know the collation and indexes of that table.
My best workaround for it is to create SYNONYMS for the tables that always point to valid tables
Ah, yes, I understand now. And I do believe that you need to make some code changes, as you have discovered.
Hi, I’ve an issue while calling Oracle Stored procedure from MS SQL Server 2012 using LINKED SERVER, It gets connected and do the execution, But sometimes, it was disconnected and says this message ‘A severe error occurred on the current command. The result if any should be discarded’. I’m not getting any clue on this issue. Do you come across anything like these kinda issue? Please share your ideas. Thanks in advance.
Could be a bug, what version of SQL Server? A quick search on Google should provide details about that error message and possible resolutions.
SQL server 2012
Nice article. Sorted out a distributed query that took over 2 hrs and ran up over 100Gb tempdb file before I cancelled. The tips offered reduced it to 20min and only 7Gb tempdb growth. Can’t say which tip specifically made the difference but I can say that paying more attention to security always has benefits regardless of whether there are performance gains
Wow! That sounds awesome, and horrifying, all at the same time! Glad the post helped you solve an issue, thanks for the comment!
Hi, thank you for this great post.
I just face very strange behavior of query contains linked server (worst it my first work week in this place so I still don’t really know the db structure neitherbusiness logic).
the sp should run every 10 sec but yesterday it start running 3 hour instead.
tried look at execution plan but it show null (seach the NET and found that it may be because of temp table they use).
and yes the query filtered by getdate() func:)
but strange it that wen I run it from SSMS it work fast so will I look at permission.
last time they solve it by recompiling and since I didn’t find fast the root cause I recompiled it and it help.
But what can explain that query work fast and in some time starting run very slow (3 hours insread of couple of sec).
the permissions and getdate issues were there always
Thanks for the comment. Any time I hear some one ask about how a query can run slow one way, but fast within SSMS, I always think of this great post: http://www.sommarskog.se/query-plan-mysteries.html
It sounds to me as if you are likely seeing the effects of parameter sniffing along with a data distribution that is skewing statistics. HTH
yeah….I aware of this and saw different options but this procedure doesn’t have parameters.
the issue is execution plane that I cannot see. I get plan handle but the execution plan dmv return null.
And if I got it correct by using getdate the optimizer will do it for unknown and change statistic will not change execution plan, so the recompile shouldn’t change anything.
but query with the time changed it behavior. and recompile help.
so notSSMS is not a question it got diff “good” execution plan (the sp as well after recompile)
What version of SQL Server? Sometimes plans that are too large will return NULL even if they still exist in cache. Perhaps you are seeing this behavior?
sorry for long question:)
AS SQL Server PFE, I think #2 has been the biggest issue for me when doing PTO to-date.
Also, INSERTS to a table on the remote server , generally seem to struggle in my experience.
Quite late to this discussion but I came across it googling linked server query issues. We recently purchased solarwinds DPA and like it a lot. I happened to uncover an issue with a linked server query that has me stumped. We’ve found a workaround, but I’d like to understand if it is a one-off problem or if we should be trying to root out other similar code.
The query is a delete query from a reporting table, and it occurs at the end of a more complicated stored procedure that populates that same table. The total rows are on the order of 6K for the table, and perhaps 2-300 will end up being deleted.
The delete query has a join to a derived table, which is the linked server query. That derived table returns 3 columns and about 100K rows — when run on its own there are no significant performance issues. However, it appears from a sql trace (and from DPA), that the derived table is being executed as if it was an inline function, or a subquery. So, for the 6K row outer table, 100K rows are being returned 6K times! I’ve never seen something like that, and it is of course entirely unexpected! By rewriting the derived table to be a select into a local temp table, then joining to that, the problem disappeared. So, not looking for a way to fix the sproc, but I would like to know if that is typical or occasional or never before seen behavior by anyone reading. Thanks!
Yes, that is interesting. What do the query plans look like before and after?
https://uploads.disquscdn.com/images/f0459418502685ff0a55d2bc07495c4f72ae8295f5b23c8744a31b6a0024ab5d.png The query plan ‘after’ can’t be rendered when I just highlight it in ssms — it says “invalid object #b” which is the temp table I insert the rows into. The ‘before’ plan was pretty simple, and had about 90% iirc of the cost in the remote query. A screen snip of the before plan is attached. Thanks. David
From Conor’s video (linked above) I learned that when it comes to linked servers and distributed queries you can “expect the unexpected”. I think you are seeing that here, and as Conor suggests you may need to have a couple of options available in case performance is poor. The QO has selected that as the best plan. It should be possible to force a plan here, but I’m not certain I would do that. I’d just go with your rewrite for now.
HTH
Hi, i just wanted to add: Try using some indexes on your big tables. (We speeded up a query just using one index on the entry column on a big serial numbers table we have…)
So if my code is currently in OpenQuery and I switch to the 4.0 DB2 client from SS 2012 (https://www.microsoft.com/en-us/download/details.aspx?id=29100) then I’m going to take a crazy performance hit?
I know it has been years since this post but this really helped me. I didn’t know that openquery could improve performance. In my case it improve my query performance drastically. Thanks!
Welcome!
Hi, I would like to subscribe for this blog to get newest
updates, thus where can i do it please help.