 I’ve stated before that great database performance starts with great database design. So, if you want a great database design you must find someone with great database experience. But where does a person get such experience?
I’ve stated before that great database performance starts with great database design. So, if you want a great database design you must find someone with great database experience. But where does a person get such experience?
We already know that great judgment comes from great experience, and great experience comes from bad judgment. That means great database experience is the result of bad judgment repeated over the course of many painful years.
So I am here today to break this news to you. Your database design stinks.
There, I said. But someone had to be the one to tell you. I know this is true because I see many bad database designs out in the wild, and someone is creating them. So I might as well point my finger in your direction, dear reader.
We all wish we could change the design or code but there are times when it is not possible to make changes. As database usage patterns push horrible database designs to their performance limits database administrators are then handed an impossible task: Make performance better but don’t touch anything.
Imagine that you take your car to a mechanic for an oil change. You tell the mechanic they can’t touch the car in any way, not even open the hood. Oh, and you need it done in less than an hour. Silly, right? That is just as silly as when you go to your database administrator and say: “we need you to make this query faster and you can’t touch the code”.
Lucky for us the concept of “throwing money at the problem” is not new as shown by this ancient IBM commercial.
Of course throwing money at the problem does not always solve the performance issue. This is the result of not knowing what the issue is to begin with. You don’t want to be the one to spend six figures on new hardware to solve an issue with query blocking.
Even after ordering the new hardware it takes time before arrival, installation, and the issue resolved. What can you do in the meantime to improve performance without touching code?
I put together this list of items to help you fix database performance issues without touching code. Use this as a checklist to research and take action upon before blaming code. Some of these items cost no money, but some items (such as buying flash drives) might. What I wanted to do was to provide a starting point for things you can research and do yourself.
As always: You’re welcome.
Examine your plan cache
If you need to tune queries then you need to know what queries have run against your instance. A quick way to get such details is to look inside the plan cache. I’ve written before about how the plan cache is the junk drawer of SQL Server. Mining your plan cache for performance data can help you yield improvements such as optimizing for ad-hoc workloads, estimating the correct cost threshold for parallelism, or which queries are using a specific index. Speaking of indexes…
Review your index maintenance
Assuming you are doing this already, but if not then now is the time to get started. You can use maintenance plans, roll your own scripts, or use scripts provided by some SQL Server MVPs. Whatever method you choose, make certain you are rebuilding, reorganizing, and updating statistics only when necessary. I’d even tell you to take time to review for duplicate indexes and get those removed.
Index maintenance is crucial for query performance. Indexes help reduce the amount of data that searched and pulled back to complete a request. But there is another item that can reduce the size of the data searched and pulled through the network wires…
Review your archiving strategy
Chances are you don’t have any archiving strategy in place. I know because we are data hoarders by nature, and only now starting to realize the horrors of such things. Archiving data implies less data, and less data means faster query performance. One way to get this done is to consider partitioning. (Yeah, yeah, I know I said no code changes; this is a schema change to help the logical distribution of data on physical disk. In other words, no changes to existing application code.)
Partitioning requires some work on your end, and it will increase your administrative overhead. Your backup and recovery strategy must change to reflect the use of more files and filegroups. If this isn’t something you want to take on then instead you may instead want to consider…
Enable page or row compression
Another option for improving performance is data compression at the page or row level. The tradeoff for data compression is an increase in CPU usage. Make certain you perform testing to verify the benefits outweigh the extra cost. For tables that have a low amount of updates and a high amount of full scans then data compression is a decent option. Here is the SQL 2008 Best Practices whitepaper on data compression which describes in detail the different types of workloads and estimated savings.
But, if you already know your workload to that level of detail, then maybe a better option for you might be…
Change your storage configuration
Often this is not an easy option, if at all. You can’t just wish for a piece of spinning rust on your SAN to go faster. But technology such as Windows Storage Spaces and VMWare’s VSAN make it easy for administrators to alter storage configurations to improve performance. At VMWorld in San Francisco I talked about how VSAN technology is the magic pixie dust of software defined storage right now.
If you don’t have magic pixie dust then SSDs are an option, but changing storage configuration only makes sense if you know that disk is your bottleneck. Besides, you might be able to avoid reconfiguring storage by taking steps to distribute your I/O across many drives with…
Use distinct storage devices for data, logs, and backups
These days I see many storage admins configuring database servers to use one big RAID 10, or OBR10 for short. For a majority of systems out there the use of OBR10 will suffice for performance. But there are times you will find you have a disk bottleneck as a result of all the activity hitting the array at
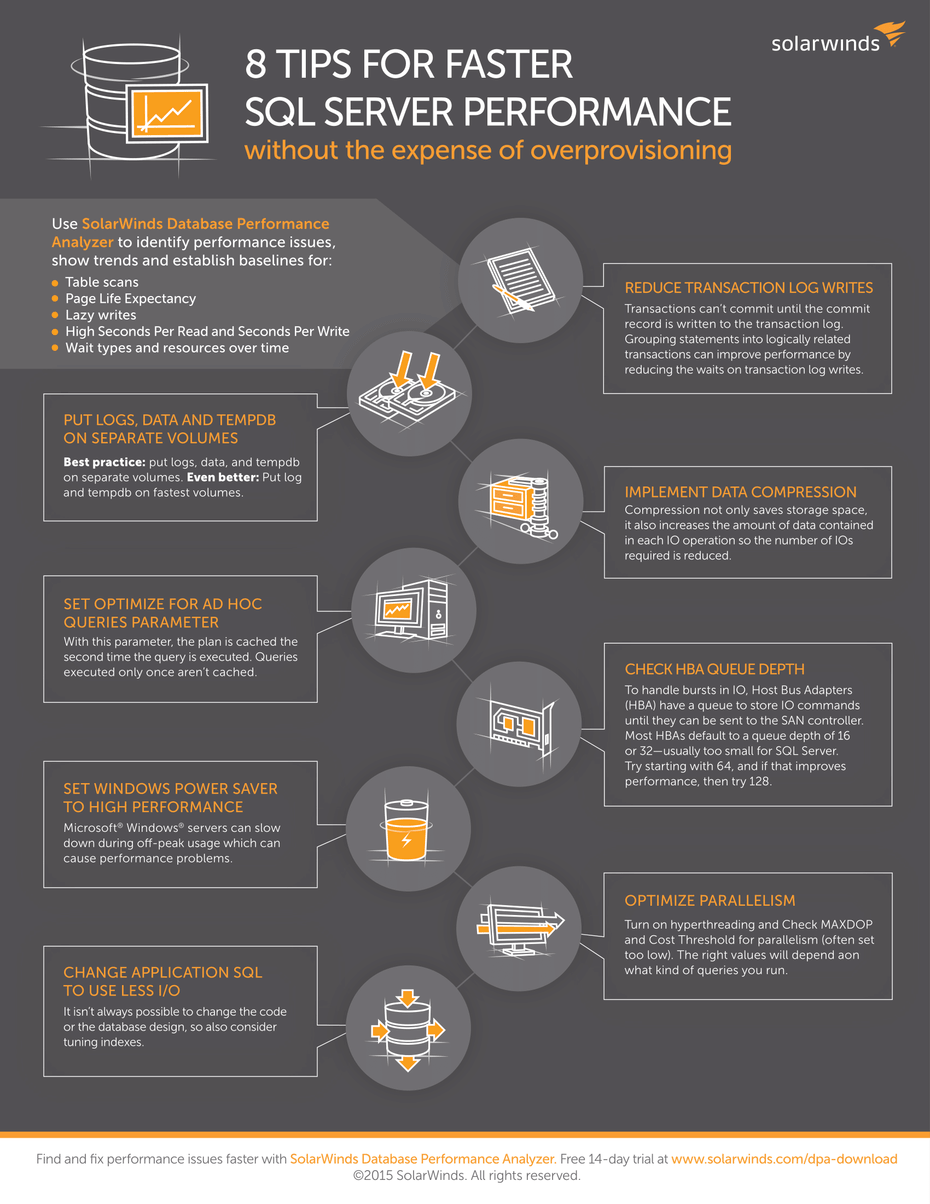 once. Your first step is then to separate out the database data, log, and backup files onto distinct drives. Database backups should be off the server. Put your database transaction log files onto a different physical array. Doing so will reduce your chance for data loss. After all, if everything is on one array, then when that array fails you will have lost everything.
once. Your first step is then to separate out the database data, log, and backup files onto distinct drives. Database backups should be off the server. Put your database transaction log files onto a different physical array. Doing so will reduce your chance for data loss. After all, if everything is on one array, then when that array fails you will have lost everything.
Another option is to break out tempdb onto distinct array as well. In fact, tempdb deserves its own section here…
Optimize tempdb for performance
Of course this is only worth the effort if tempdb is found to be the bottleneck. Since tempdb is a shared resource amongst all the databases on the instance it can be a source of contention. That is why we have lots of information on how to optimize tempdb for performance as well as trace flags.
We operate in a world of shared resources, so finding tempdb being a shared resource is not a surprise. Storage, for example, is a shared resource. So are the series of tubes that makes up your network. And if the database server is virtualized (as it should be these days) then you are already living in a completely shared environment. So why not try…
Increase the amount of physical RAM available
Of course, this only makes sense if you are having a memory issue. Increasing the amount of RAM is easy for a virtual machine when compared to having to swap out a physical chip. OK, swapping out a chip isn’t that hard either, but you have to buy one, then get up to get the mail, and then bring it to the data center, and…you get the idea.
When adding memory to your VM one thing to be mindful about is if your host is using vNUMA. If so, then it could be the case that adding more memory may result in performance issues for some systems. So, be mindful about this and know what to look for (link).
Memory is an easy thing to add to any VM. Know what else is easy to add on to a VM?
Increase the number of CPU cores
Again, this is only going to help if you have identified that CPU is the bottleneck. You may want to consider swapping out the CPUs on the host itself if you can get a boost in performance speeds. But adding physical hardware such as a CPU, same as with adding memory, may take too long to physically complete. That’s why VMs are great, as you can make modifications in a short amount of time.
Since we are talking about CPUs I would also mention to examine the Windows power plan settings, this is a known issue for database servers. But even with virtualized servers resources such as CPU and memory are not infinite…
Reconfigure VM allocations
Many performance issues on virtualized database servers are the result of the host being over-allocated. Over-allocation by itself is not bad. But over-allocation leads to over-commit, and over-commit is when you see performance hits. You should be conservative with your initial allocation of vCPU resources when rolling out VMs on a host. Aim for a 1.5:1 ratio of vCPU to logical cores and adjust upwards from there always paying attention to overall host CPU utilization. For RAM you should stay below 80% total allocation, as that allows room for growth and migrations as needed.
You should also take a look at how your network is configured. Your environment should be configured for multi-pathing. Also, know your current HBA queue depth, and what values you want.
Summary
We’ve all had times where we’ve been asked to fix performance issues without changing code. The items listed above are options for you to examine and explore in your effort to improve performance before changing code. Of course it helps if you have an effective database performance monitoring solution in place to help you make sense of your environment. You need to have performance metrics and baselines in place before you start turning any “nerd knobs”, otherwise you won’t know if you are have a positive impact on performance no matter which option you choose.
With the right tools in place collecting performance metrics you can then understand which resource is the bottleneck (CPU, memory, disk, network). Then you can try one or more of the options above. And then you can add up the amount of money you saved on new hardware and put that on your performance review.

Tom, there’s another short-term bandaid that’s available to DBAs – Plan Guides. I know there’s mixed opinions about them but when they work like you want/need them to they can be a real life-saver. On more than one occasion I’ve been called in to assess a server running at 100% CPU but I couldn’t change any code and plan guides let me get things back under control until a proper fix for the code that caused the issue could make its way through the deployment process.
That’s another great option for people to consider. Thanks for the comment!
Past all the other options, Resource governor can also allocate resources better if one workload is stomping on another.
Another good addition, thanks for sharing! I don’t think of RG as being a way to make things faster, but you CAN use RG to make some workloads “play nicely” with others. Thanks!
Thanks for that, what about understanding the app :-)?
You are welcome, thanks for reading!
thanks for the sharing, really good one, it will help for us.
Always happy to help!