SQL Data Discovery and Classification
February 28, 2018
The new version of SQL Server Management Studio (v17.5) brings with it a new feature: SQL Data Discovery and Classification. You might recall that in SSMS 17.4 the Vulnerability Assessment feature was added. So, that’s two new features in the last two releases. This is the beauty of de-coupling SSMS from the SQL Server install media. We get more features, faster. But I digress.
The SQL Data Discovery and Classification feature will seem familiar to anyone working with Dynamic Data Masking in Azure. Both features use T-SQL to parse the names of columns to identify and classify the data. (This feature is also available in the Data Migration Assistant, where you can get a list of columns that would benefit from either Dynamic Data Masking or Always Encrypted.)
The SQL Data Discovery and Classification feature will help users discover, classify, and label columns that contain sensitive data. The feature also allows for the generation of reports for auditing purposes. With GDPR less than three months away, this could be the one feature that helps your company remain compliant.
Running SQL Data Discovery and Classification
Using the Data Discovery and Classification tool is easy, just select a database and right-click. Go to ‘Tasks’, then ‘Classify Data…’. Here is an example using a test GalacticWorks database:

My GalacticWorksTest database has only one table, a copy of the AdventureWorks2012.Sales.CreditCard table. You can see the results of the scan here:

I’ve highlighted the ‘Information Type’ and ‘Sensitivity Label’ column headers. I want to make certain you understand these columns represent dropdown windows, allowing you to alter both, as needed.
The options for Information Type are as follows: Banking, Contact Info, Credentials, Credit Card, Date Of Birth, Financial, Health, Name, National ID, Networking, SSN, Other, and [n/a]. Here’s what the drop down looks like:
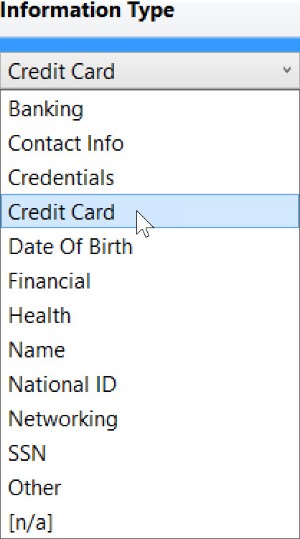
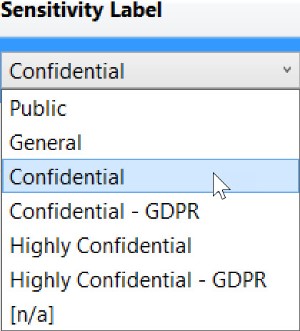
The options for Sensitivity Label are as follows: Public, General, Confidential, Confidential – GDPR, Highly Confidential, Highly Confidential - GDPR, and [n/a]. Here’s what the drop down looks like:
SQL Data Discovery and Classification with Non-English Names
Since the feature is parsing column names, we will create a new table and use non-English names. We will also use abbreviations for column names for those of you old experienced enough to remember when abbreviations were in vogue.
OK, let’s create a new table:
CREATE TABLE [Sales].[Tarjeta](
[TarjetaCreditoID] [int] IDENTITY(1,1) NOT NULL,
[TarjetaTipo] [nvarchar](50) NOT NULL,
[TarjetaNumero] [nvarchar](25) NOT NULL,
[TARNUM] [nvarchar](25) NOT NULL,
[ExpMonth] [tinyint] NOT NULL,
[ExpYear] [smallint] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Tarjeta_TarjetaCreditoID] PRIMARY KEY CLUSTERED
([TarjetaCreditoID] ASC
)ON [PRIMARY])
ON [PRIMARY]
GO
I’ve created a table almost identical to the Sales.CreditCard table, except that I am using Spanish names for credit (‘credito’), card (‘tarjeta’), number (‘numero’), and type (‘tipo’). I’ve also added a column TARNUM, an abbreviation for the TarjetaNumero column. That’s the column that would have actual credit card numbers.
We will re-run the classification again (make sure you close the first results, otherwise you won’t get a refresh with the new table included). Also note that I don’t need data in the table for this feature to evaluate the columns. I haven’t loaded any rows into Sales.Tarjeta, and here’s the result (I’ve scrolled down to show the three new rows):

The Data Discovery and Classification tool identified three columns: ExpMonth, ExpYear, and CreditoID. However, it missed TarjetaNumero and TARNUM, which would have the actual credit card numbers. The TarjetaCreditID column has no card number, just an IDENTITY(1,1) value used for a primary key.
One last item of interest. When a column is classified, the details are stored as extended properties. Here’s an example:

You can see the Data Discovery and Classification feature does not flag the columns I created for this test. Because the feature focuses on keywords, it’s expected behavior that columns will be skipped. There are two reasons why. First is the fact that the use of keywords has some cultural bias. For example, ‘SSN’ is flagged as a keyword for the American ‘Social Security Number’. But in the Netherlands it’s possible to have ‘SOFINR’ as a column name abbreviation for ‘Social Fiscal Number’, and SOFINR is currently not flagged.
The second reason is that the feature only supports English, and offers partial support for a handful of non-English languages (Spanish, Portuguese, French, German, and Italian). [As I’m writing this I am at SQL Konferenz in Germany I found that ‘Personalausweis’, the name for the German Identification card, is flagged.] However, the MSDN I provided earlier makes no mention of supported languages or collations. I’m hoping that the MSDN pages get update to reflect the languages and collations that are supported, to avoid any confusion for users.
Data Discovery and Classification Reports
Once you have reviewed and classified your data you will want to run a report. Using AdventureWorks2008 as an example, I will accept all 39 recommendations, click ‘Save’, and then click ‘View Report’. Here’s the result:

The report shows that AdventureWorks2008 database has 39 distinct columns in 19 distinct tables that have been classified. This is the information you can now hand over to your audit team.
This report is at the database level. That means you will need to roll your own solution to get the details from many databases at the same time. It should be possible to use some Powershell voodoo to extract the data. Or, better yet, fire up PowerBI and use that to build your own dashboard.
Summary
The SQL Data Discovery and Classification feature is a great first step by Microsoft to help users understand where sensitive data may exist in their enterprise. This is also a good time to remind you why having a data dictionary is important. But even with all the right tools in place, all the right people, using all the right knowledge, you will still miss a column of sensitive data at times.
That’s because life is dirty, and so’s your data. Identifying and classifying data is not an easy task. You won’t get a perfect result with a simple right-click of a mouse. It takes diligence on the part of the data professional to curate the necessary metadata for data classification. Not every data professional has the time or patience for such efforts.
But the Data Discovery and Classification tool is great first step forward. I can’t wait to watch this feature as it grows.