HOW TO: Recreate SQL Server Statistics In a Different Environment
July 16, 2015
Did you know table and index statistics are the most important piece of metadata for your database?
The reason for this has to do with how SQL Server (and other database engines) build query execution plans. The query optimizer builds an execution plan based upon the statistical data available at the time. If you have bad statistics you are gong to have sub-optimal plans, with poor performance being the result.
Statistics are so important for performance that we have a host of scripts and tips and tricks on how to keep your statistics as up to date as possible. Even novice administrators reach for the UPDATE STATISTICS statement whenever they have a performance issue they can’t solve right away and they need a quick fix.
Knowing that statistics are so important you might think it crazy for trying to find a way to adjust the statistics in order to make SQL Server think it has more rows than it really does.
Why would anyone want to do this? Great question. I can think of three reasons why this would be important.
First, you may not have enough space to do a restore. You may find that you don’t have enough space on your local machine to restore that 30TB production database. This makes it hard to research performance issues at times, which leads to developers being granted access to production in order to do some “break-fix” repair work. That’s not ideal.
Second, agile can be woefully inadequate for performance testing. Just because that code works against 100 rows in development doesn’t mean it will run well against millions of rows in production. Most agile coding seems to focus on functionality first and rarely considers the effects of increased data volumes as time goes on. Being able to manipulate the object statistics allows for enhanced testing plans and a better chance at a successful production deployment.
Lastly, you may not want people to see your data. You may need help from someone, say at Microsoft support, but you need to keep your data private. You can provide them the object DDL and allow them to examine query plans without them seeing your all of your sensitive data. More on this later.
The UPDATE STATISTICS Statement
Now that I know why I might want to do this, I need to figure out what is possible. Lucky for me the UPDATE STATISTICS entry over at MSDN lists some extra options at the bottom of the syntax that appear to be helpful:
<update_stats_stream_option> ::=
[ STATS_STREAM = stats_stream ]
[ ROWCOUNT = numeric_constant ]
[ PAGECOUNT = numeric_contant ]
And further down the page you will find this remark:
<update_stats_stream_option> Identified for informational purposes only. Not supported. Future compatibility is not guaranteed.
I have no idea why this MSDN entry would even include the syntax for what appears to be an undocumented option. But they did, so now I’m curious to know how to use these options. A quick Google Bing search and I come back with this blog post.
The post has an example of how to use the syntax for the ROWCOUNT and PAGECOUNT options only. What good is altering the ROWCOUNT and PAGECOUNT if you don’t know the distribution of the data? Not much, if you ask me. The object statistics contain more than just rowcounts and pagecounts, there is a histogram as well that tells the optimizer the distribution of the data for the object. I know I need to recreate the histogram data somehow.
So that’s when I decided to stop Googling Binging Banging searching for details on an undocumented feature and I dropped an email to Tim Chapman (blog, @chapmandew) who was shocked to hear that I had no idea about these undocumented features. I asked about the STATS_STREAM option and got back a reply that was like a siren song:
“That’s the histogram.”
Tim, you can sing that to me again, anytime. This is one of those times where I remember how much I love working with SQL Server and to find something new after all these years.
How To Recreate SQL Server Statistics In a Different Environment
First, let’s grab a query we can examine in detail. I’ll use this one inside of AdventureWorks2014. It’s a simple join and it results in 121,317 rows being returned.
SELECT *
FROM Production.Product p
INNER JOIN Sales.SalesOrderDetail s
ON s.ProductID = P.ProductID
I will turn on ‘Include Actual Execution Plan’ inside of SQL Server Management Studio (SSMS) and see that the query plan has this shape:
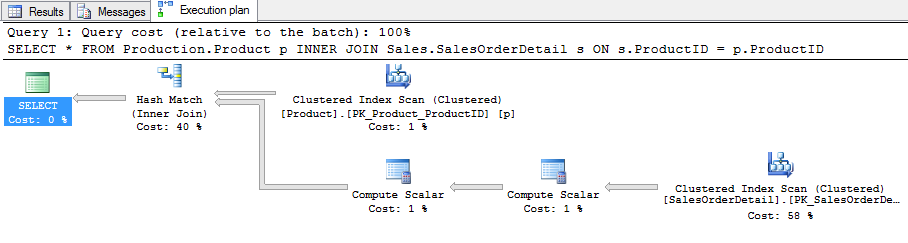
All good so far. What I want to do now is take these two tables and recreate them in a different environment but schema only, no data. I will script out the DDL for the two tables by right-clicking on the database name inside of SSMS and navigating to the ‘Generate Scripts’ task:
For this example I will select my Production.Product table:

Click next and on the following screen we want to find the Advanced button:

Hidden inside of the advanced options is this little gem:

That’s right, I can script out the stats and the histogram! Here’s what they will look like when done (binary value truncated for displaying here):

If you were thinking “hey, how can I get this without using the GUI and generating a script” you are not alone because I was wondering the same thing and found that the DBCC SHOW_STATISTICS command allows for the STATS_STREAM option. And, just as with the UPDATE STATISTICS command, it has the same message about it being included for informational purposes only. So, this command will return the same information as the DDL script we are generating:
DBCC SHOWSTATISTICS ("Sales.SalesOrderDetail", PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID)
WITH STATS_STREAM
What this means is we can script this action if so desired and make it a part of a repeatable testing process. That’s good to know.
OK, we’ve got what we need, now let’s put these to work for us. Next, I will create an empty database:
CREATE DATABASE TestStats
Now we will run the DDL but I am only going to create the tables, not update any statistics yet. Why? Because I want to know the plan shape before I modify the underlying stats, just as a reasonable check. So let’s create the tables and run our SELECT statement and take a look at the plan:

OK, that’s good, it’s a very different plan, and that’s because the stats on the table reflect there is no data. So now I will run the statements to create and update the statistics from AdventureWorks2014 and let’s look at the estimated plan now:

The plan is identical to the one from AdventureWorks2014, as expected. Success!
This means it is possible for me to adjust the stats WITHOUT the need to load actual data. That allows for me to examine query plans between environments for any of the use cases described at the beginning.
Remember when I promised “more on this later”? Well, that time is now.
The histograms we migrated contain data for the leading column of the index. I want you to understand that there is some data that will be migrated and it is possible that this data could be considered sensitive. For an example of this let me show you what happens if I run the DBCC SHOW_STATISTICS command against an index in the Person.Address table in AdventureWorks2014 as follows:

So, yeah, be careful out there.
As great as all of this might seem I must remind you that YOU ARE SCREWING WITH YOUR STATS! Put things back when you are done! Don’t make me use more exclamation points! I’d advise that when you do this kind of testing you create new, empty databases that no one is using. Otherwise you run the risk of having the alterations affecting performance for others, causing more pain and grief than necessary.
Not to mention the phone calls telling you all the queries are returning zero rows. Nobody wants that.
Enjoy!