SQL Server 2014 has a lot of shiny new features. One of the brightest is In-Memory OLTP Hekaton, something I have been optimistic about (get the pun?) ever since I saw it at the PASS Summit in 2012. These days there is no shortage of information available to day regarding how Hekaton is full of awesome and how it works beneath the covers.
Well, except for one piece of information. In what might be blatantly obvious to everyone on Earth, Hekaton objects are stored in the memory space used by SQL Server. In what might not be so obvious, Hekaton objects are stored alongside buffer pool pages and memory internal structures controlled by the “max server memory” configuration setting.
That’s right, the max server memory setting controls the amount of memory not just for data pages in the buffer pool, but also for Hekaton objects and data. For some reason the MSDN page doesn’t mention what memory regions are included. I don’t think they ever have included this information, either. But I believe it would be a nice improvement if they did. There is this KB article that explains how the max memory setting in SQL 2012 included more than just the buffer pool, but I haven’t found any similar for SQL 2014 and Hekaton.
The only thing I could find was this article that shows there are specific memory clerks (named MEMORYCLERK_XTP), as well as this key sentence:
Memory allocated to the In-Memory OLTP engine and the memory-optimized objects is managed the same way as any other memory consumer within a SQL Server instance.
So, yeah, that tells me it is included inside the max server configuration setting, based upon the enhancements included in SQL 2012 that expanded the max server memory configuration option beyond just buffer pool pages.
Ok then, why does this matter? Great question. Let me give you two reasons.
1. When Hekaton Needs More Memory, Your Buffer Pool May Shrink
Makes sense, right? If not, here’s a picture of what will likely happen as SQL Server 2014 needs more memory for Hekaton objects (the ‘max server memory’ axis denotes the max server memory configuration setting, not the total amount of memory on the server):
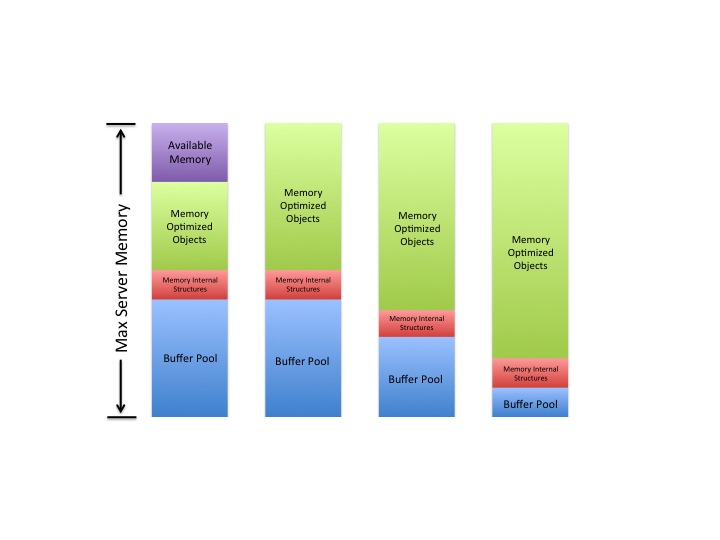
As the need for more memory for Hekaton objects grows, the first memory area it will take from is whatever available memory exists (but still within the max server memory configurations setting). After that, it is the buffer pool that will be likely be squeezed.
Since most of us qualify as what I call “data hoarders” (i.e., we only acquire more data, we rarely get rid of it, or archive it), there is a very good chance those memory optimized tables are only going to increase in size over time, and likely at the expense of your buffer pool.
Which brings me to my second point…
2. You Need To Properly Estimate How Much Memory You Need for Hekaton
Fortunately there is a way for you to guesstimate how much memory space you need for your Hektaon objects as Microsoft details in this MSDN post.
The TL;DR version of that MSDN article is this: you can’t just use the current size of the table and indexes as your estimate. You need to do a little extra math.
You can think of the estimate as being something this simple:
Hekaton memory needed = Size of the Table + Sum of all Index sizes + row versioning
For most people the size of a table is estimated by taking the size a row and multiplying by the number of rows. But for a Hekaton table you need to include some extra information such as a 24 byte row header and 8 bytes for each index you are thinking of creating. Add those to the size defined by the data types, then multiply by the number of rows and you’ve got your max table size.
Next, you need to estimate the size of the indexes. Hekaton has two types of indexes for you to use: hash indexes and non-clustered (or range) indexes.
Hash indexes are easier to estimate as they will have a fixed size based upon the bucket count. Whatever value you specify for the bucket count gets adjusted to the next highest power of 2 (i.e., if you define a bucket count of 100,000, SQL Server will actually use 131,072). You simply take that number and multiply by 8 to arrive at the number of bytes needed for the hash index.
Non-clustered (or range) indexes are dynamic in size, but it is essentially the number of unique rows multiplied by the sum of the key column data types plus 8 bytes for the pointer size.
Lastly, we need an estimate for the number of row versions that will need to be kept in memory due to DELETE and UPDATE activity. The MSDN article has a formula that tells you to take the number of rows in your table and multiply by the longest transaction (measured in seconds) and multiply that by the peak number of transactions. That seems like a lot of math, even for me. And what I don’t like about this method is that this requires you to be running your workload in Hekaton before you can accurately estimate the memory you need to run the workload in Hekaton.
Yeah. That. Chicken, meet egg.
I think a practical upper bound for row versioning is 2. Just plan at the start that you need to double whatever it is you come up with as a result for the size of the table and indexes. That’s as good a starting point as any without actually having to be running in Hekaton. Then, after you are running in Hekaton, you can come back and do the hard math to refine your estimate for your ongoing needs.
How I Would Estimate Hekaton Max Server Memory
The process flow I would follow for estimating memory requirements in SQL Server 2014 is this:
- Get current number of rows in the table.
- Get current size of row by adding up data types, row header (additional 24 bytes) and 8 bytes for each index.
- Multiply (1) and (2) and set aside the result.
- For each hash index, get the bucket count, round up to the next highest power of 2, and then multiply by 8.
- Get sum of all hash indexes in (4) and set aside.
- For each non-clustered index, get the width of the key columns, add 8, then multiply that by the number of unique rows.
- Get sum of all non-clustered indexes in (6) and set aside.
- Add (3), (5), and (7) together.
- Multiply the result from (8) by 2, this is the guesstimate that includes row versioning.
But we are still not done yet, because this is just our immediate needs. We want to take this and think about our expected growth for the next 18 months or longer. So, we will do this all over again, but increase the row counts by 1.5 or whatever you think makes sense for the time period you are forecasting. While it may be great to have a result that says you need 32GB of RAM now for your Hekaton objects, you need to understand that in 18 months these objects may be consuming up to 48GB of RAM, and along the way possibly squeezing out more and more buffer pool pages.
If you are using a lot of variable columns and you don’t know how to get an estimate for your rowsize, use the sys.dm_db_partition_stats DMV. You can find the number of used pages, and divide by the number of rows to arrive at an average that you can then use above. This is also the place where I remind you that monitoring the sys.dm_os_memory_clerks DMV on a regular basis is going to help you to understand just how much memory is being allocated to Hekaton objects over time. If you are going to deploy Hekaton, you are going to want to make certain you pay more attention to that DMV than you have before.
OK, let’s say we get this done and we find that we need more memory than we expected. What can we do then? Well, one option would be to run out and buy more RAM, but ultimately that won’t solve the issue of your buffer pool shrinkage as your Hekaton objects increase.
This Is Why We Have Buffer Pool Extensions
If you find that Hekaton requires too much RAM for your liking, or is starting to slowly consume more RAM at the expense of your buffer pool pages, then this would be a perfect use case for Buffer Pool Extension (BPE) in SQL Server 2014. In a nutshell, BPE allows you to use a solid-state drive (SSD) extension for the SQL Server buffer pool.
Using the 48GB estimate from above, let’s consider a server that currently has 128GB of RAM installed. We can configure the max memory for the instance to be 120GB of RAM, which means that after subtracting out the 48GB for Hekaton objects we would have at most 72GB of RAM left.
And just like that, 128GB of server RAM got downsized to only 72GB of RAM available for data pages, plan cache, CLR, etc. My guess is that someone, somewhere, will see that only 72GB of 120GB is available as an issue. Of course, everything is a tradeoff. The 48GB of RAM aren’t being wasted, just used by something else.
But with the use of BPE you can get back those 48GB of RAM and a whole lot more. You are allowed to extend the pool by up to 32x the max server memory setting. In this case that is 3,840GB, or more than 3TB of RAM extension for this example! And while 32x is possible, Microsoft recommends you start a tad more conservative, on the order of 4x to 8x more. Still, even 4x more would be 480GB of RAM here, probably more than enough (as well as affordable) for your buffer pool needs.
Summary
When moving to SQL Server 2014 and the use of Hekaton (In-Memory OLTP) objects, you will want to properly estimate how much space is going to be needed. Failure to do so will result in your buffer pool not being able to keep as many data pages in memory as you were expecting, resulting in degraded performance at the expense of enhanced performance for the Hekaton objects. With BPE you can get back the memory for your data pages in the buffer pool.

why not to configure memory for Hekaton using Resource Governor and Monitor via alerts which will be more proactive.
Jay,
Sure, that’s a fine way of managing objects after they are migrated.
You can’t create the object in Hekaton unless SQL Server has enough memory to hold it, therefore you need to find a way to estimate the amount of memory needed. And, when you create it, your buffer pool pages may be the victim.
HTH